Hoy, 6 de octubre VMware sacó la nueva versión de vSphere 7 Update 1, esta versión tiene algunos cambios sobre componentes clave de vSphere (Como ser DRS) por lo que me gustaría hacer una revisión rápida de estas actualizaciones.
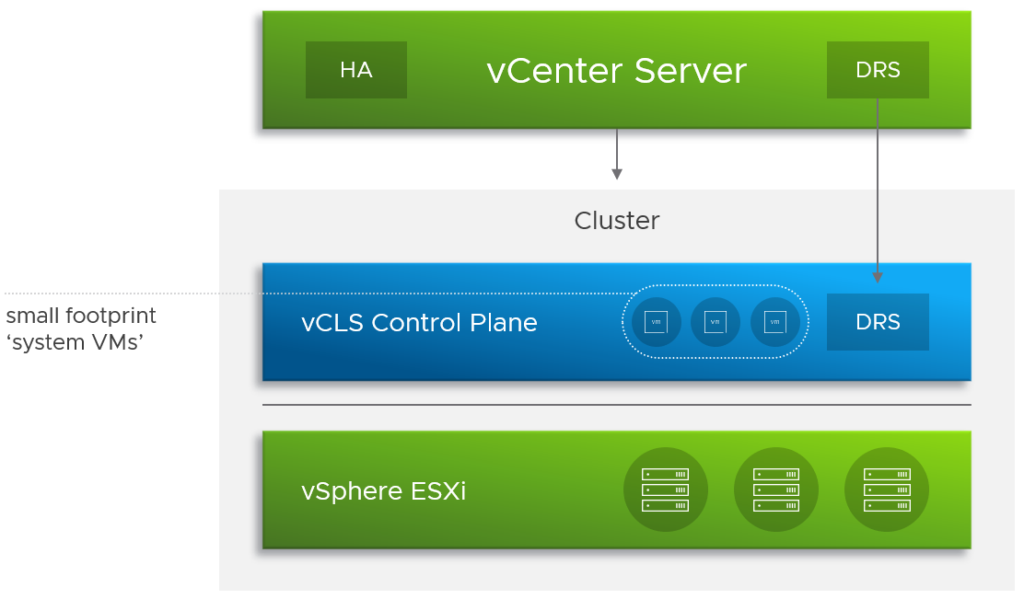
vSphere Clustering Service (vCLS)
Para contarte que es, primero te cuento que viene a resolver: Algunos servicios a nivel cluster en vSphere (por ejemplo DRS, vSphere HA o vCenter HA) dependen de vCenter, si por algún motivo vCenter falla (algo que queremos evitar a toda costa, pero que todos hemos visto) estos servicios se pueden ver afectados. vSphere Clustering Service agrega un plano de control distribuido (similar al de NSX-V) de hasta 3 máquinas virtuales (basadas en Photon) que forman un cluster de quorum y ejecutan y controlan los servicios a nivel cluster de vSphere
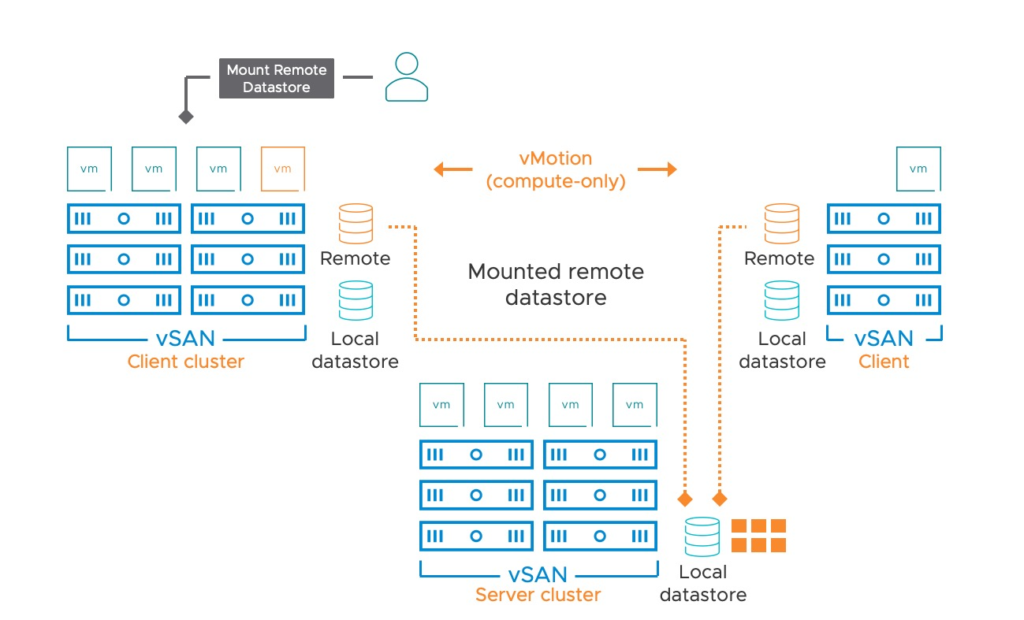
Esta feature me parece algo hermoso. Lo que hace es permitirte presentar storage de vSAN entre distintos clusters dentro del inventario de vCenter. Te da la posibilidad de escalar hasta 64 hosts por cluster y es completamente agnóstico de hardware (siempre y cuando sean nodos vSAN ready)
Ya sabemos que VMware está empujando fuerte para meterse al mercado de Kubernetes. Algunas de las mejoras que implementaron en esta nueva versión de Tanzu Kubernetes Grid (TKG) service (El Kubernetes engine de VMware) son: Bring your own Networking/Storage/Load Balancer Le permite a las organizaciones aprovechar sus inversiones y conocimiento en Plugins para Kubernetes, siendo posible utilizar productos nativos de VMware (NSX/vSAN/etc.) o productos de terceros.
vSphere Ideas
Ahora los clientes con un contrato de soporte activo pueden cargar feature requests desde el vSphere cliente. Este cambio está muy bueno desde la perspectiva del usuario final, ya que antes el proceso era tedioso y poco claro.
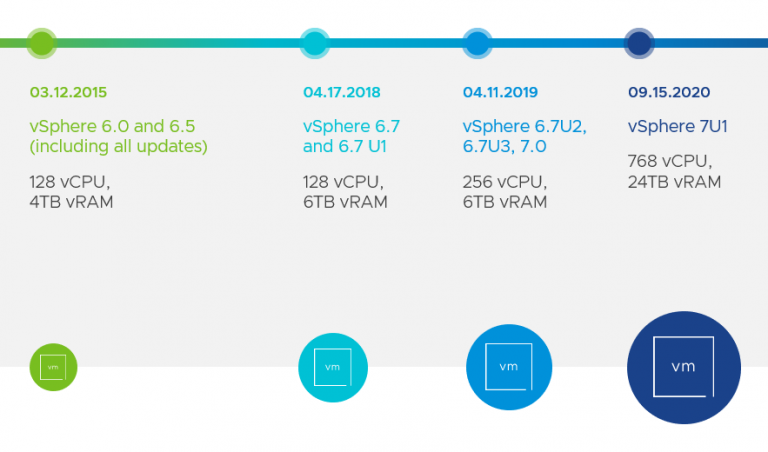
Optimización para Monster VMs
Se revisaron los máximos de vSphere y ahora soporta hasta 24TB de memoria y 768 vCPU en una sola VM, teniendo en cuenta monster VMs.
Adicionalmente, se aumentó el máximo de hosts por cluster a 96.
Por último, aunque no es una feature es un gran esfuerzo de todos los equipos de VMware, se revisó la terminología que usa la suite para hacerla más inclusiva. Evitando términos como Master y Slave, siguiendo con la movida que arrancó en Silicon Valley a Raíz del Black Lives Matter.
Esta semana fue la edición 2020 del VMworld y hubo una palabra que se repitió más que nada: Kubernetes. El año pasado VMware compró Pivotal y a los pocos días anunciaron, Project Pacific, su re-ingeniería de la plataforma. Este año tuve la suerte de hacer cursos de vRealize Automation 8 y algo que me llamó la atención es que lo que antes eran servicios, ahora se maneja con pods dentro de los appliances.
Cómo hasta ese entonces no había visto mucho de Kubernetes, más que alguna charla y o algo en la facu, me decidí a investigar y “enseñarme” cómo funcionan.
Me gustaría compartirles este glosario con una descripción para que todos puedan entender que es este servicio que llegó para quedarse. Al final del post, comparto algunos recursos que me sirvieron para aprender y son 100% gratuitos.
¿Qué es Kubernetes?
Kubernetes es una plataforma Open-Source para administrar y orquestar containers que facilita la configuración declarativa y la automatización.
¿Quién desarrolla Kubernetes?
Kubernetes comenzó como un proyecto de Google y lo hicieron Open-Source en 2014, actualmente lo mantiene Cloud Native Foundation y los mayores vendors de tecnología tienen sus implementaciones. Por ejemplo RedHat con Openshift o VMware con Tanzu, entre otros.
Kubernetes en griego significa timonel, por eso el logo es un timón.
¿Por qué Implementar Kubernetes?
Para responder esta pregunta hay que ir un par de años atrás en el datacenter y entender cuáles son las problemáticas que viene a resolver.
Si nos fijamos en la primera etapa: todos los servidores eran físicos (bare metal), es decir, por cada aplicación que manteníamos necesitábamos tener un servidor con sus recursos (CPU/Memoria/NIC’s/Storage), un sistema operativo y sus aplicaciones: Este modelo aumentaba los costos de hardware, mantenimiento y era poco resiliente a fallas. Sumado a esto, la instalación y configuración de servidores bare-metal era (y sigue siendo) un proceso tedioso y lento.
Para resolver ese problema llegó la virtualización: La virtualización permite colocar múltiples máquinas virtuales (VMs) en un solo servidor físico (Hipervisor) esto permite consolidar recursos (CPU, Memoria, Storage) , acelerar tiempos de aprovisionamiento y da un mayor nivel de seguridad ya que una VM no puede acceder a los recursos de otra VM. Cada VM tiene su propio sistema operativo y aplicaciones.
Containers: Los containers son parecidos a las máquinas virtuales, pero tienen aislamiento flexible, por lo que comparten el sistema operativo entre distintas Apps. Al igual que las VMs los containers tienen su propio CPU, Memoria, tiempo de procesamiento y demás, pero no dependen de la infraestructura, por lo que son portables.
Adicionalmente, dentro de cada container están resueltas todas las dependencias de una aplicación: es decir si yo necesito instalar LAMP debería tener alguna versión de Linux, Apache, MySQL y PHP. El container se va a asegurar de que las versiones de Apache, MySQL y PHP sea la misma en cualquier lugar que corra el container. Lo que garantiza la portabilidad. Por último, los containers fueron concebidos con la agilidad en mente, por lo que la automatización es 100% compatible. Otra cosa importante, como las Máquinas virtuales tienen el hipervisor los containers tienen el Container Engine. En este caso vamos a hablar de Docker.
En este video dan una explicación muy buena del porqué del nombre containers.
Ahora sí, ¿por qué Kubernetes? Es sabido que todos los servidores pueden fallar, y nuestro trabajo como profesionales de IT es evitar que fallen. Kubernetes está pensado desde esa premisa, sabiendo que nuestros servicios van a fallar, nos da la posibilidad de controlar el cómo se va a comportar nuestra infraestructura cuando fallen.
– Balanceo de Cargas nativo: Podemos exponer un container por IP de servicio o DNS. Si el trafico es alto Kubernetes permite balancear la carga. – Orquestación de storage: Permite automatizar la provisión de storage a tus containers. – Rollouts y Rollbacks automáticos: Permite definir manifiestos YAML con el estado deseado de nuestros containers. – Self Healing: Kubernetes reinicia, reemplaza y mata containers en base a su estado.
Kubernetes es la clave para dejar de tratar a nuestros servidores como Mascotas y empezar a tratarlos como ganado.
¿Cómo funciona Kubernetes?
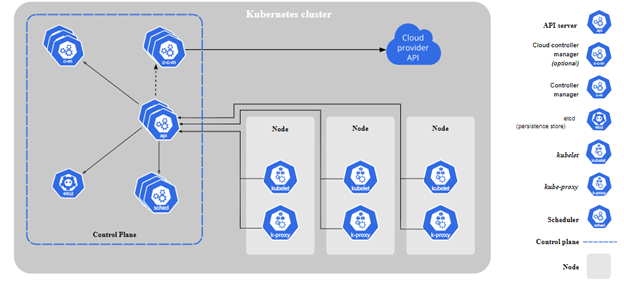
Cuando implementas Kubernetes tenés un cluster. El cluster es un conjunto de máquinas workers, o nodos, que va a correr nuestros containers, todos los clusters tienen al menos un nodo. En Kubernetes los nodos ejecutan Pods (que sería un container de containers) La implementación también tiene un plano de control que supervisa y administra los nodos y los pods. En entornos productivos, el control cluster tiene varias máquinas master y también múltiples nodos para aumentar la resiliencia del cluster.
Acá dejo un diagrama
Veamos que hace cada componente:
Componentes del Control plane:
Los componentes del control plane toman decisiones sobre los demás nodos de Kubernetes. Por Ejemplo: definir donde va a correr cada Pod, validar si hay que agregar más replicas, etc.
Estos componentes se instalan en la misma máquina por lo general, y se pueden usar clusters distribuidos como dijimos antes. En estos servidores no se ejecutan containers de usuario.
kube-apiserver:Se encarga de exponer la API de Kubernetes, el frontend del control plane de Kubernetes. Todas las interacciones que tengamos con nuestro cluster de Kubernetes van a ser mediante esta api.
etcd:Es la base de datos del cluster de Kubernetes.
kube-scheduler: Indica en que nodo se van a crear los pods.
kube-controller-manager: Unifica y administra los procesos del cluster de control. Algunos procesos que administra son: Node controller: Monitorea el estado de los nodes y notifica si alguno se cae. Replication Controller: Es el encargado de monitorear y aplicar la cantidad de replicas correctas para cada pod.
cloud-controller-manager: Te permite conectar tu cluster a un proveedor de servicios en la nube (Google Cloud, Amazon, Azure, etc) y separa los componetnes que interactúan con la nube de los que solo interactúan de forma local. Este componente solo existe en la nube, si tenés un entorno on-premise no lo vas a ver.
Componentes de los nodos:
Nota: los nodos tienen que correr sobre alguna distribución de Linux.
Container Engine: El software que se encarga de correr containers, por ejemplo Docker, containerd, podman, etc.
kubelet: Es un agente que corre en cada nodo del cluster y se asegura que los containers estén corriendo en un pod. Está hablando constantemente con el kube-apiserver para validar que los pods y servicios cumplan con el estado deseado. Adicionalmente ejecuta las acciones que le pasa el apiserver.
kube-proxy: es un proxy de red que corre en cada nodo. Se encarga de mantener las reglas de red en cada nodo. Esas reglas permiten que los pods puedan tener conectividad fuera del nodo.
Pods: es un grupo de uno o más containers, como me explico mi queridísimo Guille Deprati, es un container de containers.
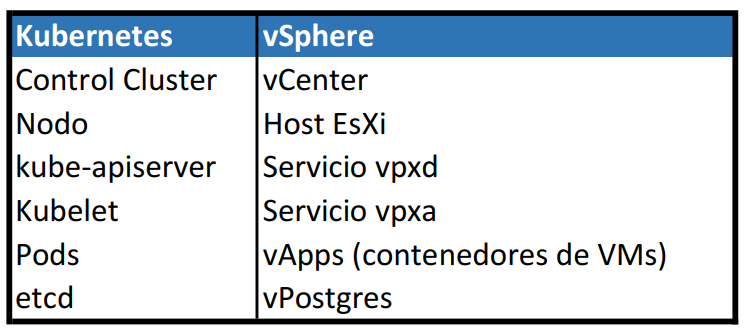
Algo que a mi me sirvió mucho para entender la arquitectura de Kubernetes es compararlo con lo que entiendo y conozco. Cómo soy administrador VMware me sirve hacer la equivalencia entre Kubernetes y vSphere.
Otro recurso importante es el Container Registry: Basicamente es un repositorio de imagenes de containers (container images) a partir de las cuales vamos a crear nuestras pods. Existen los Registros Públicos como ser Docker Hub y podemos tener registros privados dentro de nuestra organización (Red Hat Quay, Harbor, etc). Los cloud providers (AWS, Azure, Google Cloud, Alibaba) probeen su servicio de container registry.
Recursos de estudio:
Los recursos que usé durante estos meses fueron los siguientes:
Hace rato que no escribo nada y quería hacer algo sencillo y apto para todo público. Cada vez son más las personas que empiezan a estudiar programación y a veces está bueno tener un tutorial explicado en lenguaje amigo.
Prerequisitos
Cómo dije antes, vamos a necesitar tener una máquina virtual con linux para este tutorial, voy a poner los comandos para el mundo RHEL y el mundo Ubuntu
Ubuntu
Primero vamos a actualizar el listado de paquetes. $ sudo apt update
Desinstalamos versiones viejas. $ sudo apt-get remove docker docker-engine docker.io containerd runc (Si recién instalas la máquina, apt-get debería decirte que esos paquetes no estan instalados).
Instalamos los paquetes que permiten a apt hablar HTTPS $ sudo apt install apt-transport-https ca-certificates curl software-properties-common
Agregamos la clave GPG del repositorio oficial de Docker
Por defecto, el comando docker solo puede ser ejecutado por el usuario root o un usuario en el grupo docker.
Para evitar tener que tipear sudo cada vez que usamos docker hay que agregar nuestro usuario al grupo de docker.
$ sudo usermod -aG docker ${USER}
Otra opción es agregar el usuario de forma explicita, por ejemplo: $ sudo usermod -aG docker username
Para aplicar los permisos es importante que hagamos logoff con el usuario y hagamos login nuevamente.
Una vez hecho esto. Deberíamos poder correr comandos de docker.
Por ejemplo: $ docker run hello-world
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
9bb5a5d4561a: Pull complete
Digest: sha256:3e1764d0f546ceac4565547df2ac4907fe46f007ea229fd7ef28984514bcec35d
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.
...
This is the second in a series of posts discussing about VMware vSphere Availability features, how do they work and what are their requirements. Please keep in mind, the intended audience for this posts are Sysadmins that want to know a little more about vSphere. If you have been working with VMware products for a while you might find this post kind of boring.
In my last post of the series I spoke about vSphere vMotion but that’s not the only way of migrating VMs arround in VMware environments. I would like to discuss a few of them.
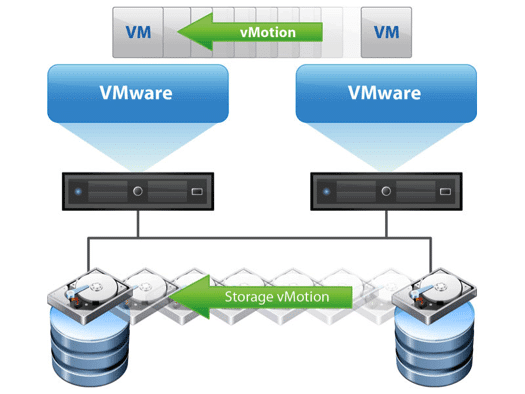
Storage vMotion
Storage vMotion was introduced in VMware Infrastructure (ESXi 3.5) and it is a feature that allows administrators to move Virtual Machines across different datastores without powering off a virtual machine.
Some of it’s key features are: – Workload migration across different physical LUN’s. – IOPS load balancing (With sDRS Datastore clusters). – Storage Capactiy Management. – The ability to perform maintenance on phyisical storage without downtime.
How Does it work? Before I explain that, please take a look at this post regarding what files compose a virtual machine. The process is the following
The user selects a VM to be migrated and a destination datastore. (Thus defining source and destination datastores and files to be migrated).
VM folder is copied to the destination datastore. (That includes all VM files but VMDK’s)
Once all files are copied a “shadow VM” is started at the destination DS and it’s idled waiting for VM disk file(s) to finish copying.
During the disk file transfer all changes to the files are tracked with changed block tracking (CBT).
svMotion iteratively repeats the CBT process during data transfer.
Once the ammount of outstanding blocks is small enough, svMotion invokes a FSR (Fast Suspend and Resume) similar to the stun on vMotion. To transfer the running VM to the idle “shadow VM”
After FSR finishes files on the source datastore are deleted and space is reclaimed.
Considerations:
Storage vMotion can be used to rename VM folders and files on datastores.
It can also be used to change VM disk provisioning.
Before the svMotion process is initiated a target datastore capacity check is done, so you can’t migrate a VM in a full datastore.
svMotion is “storage agnostic” meaning it can work with anything that can provide a VMware datastore. (iSCSI, FCoE, vSAN, NFS, NAS, etc)
svMotion might cause issues on IO intensive applications such as databases. Please keep that in mind.
The max concurrent svMotion migrations is 16, nevertheless doing this can cause performance degradation on the storage array.
While vMotion requires a dedicated vmkernel TCP/IP stack for traffic. Storage vMotion migrates data two ways: over FC switches in case you are using Fiber Channel or using Management or Provissioning interfaces.
Requirementsand limitations:
You need vCenter to do a storage vMotion
ESXi host in which the VM is running must have access to source and destination datastores.
ESXi on which the virtual machine is running must have at least Standard licenses.
Storage vMotion during VMware tools installation is not supported.
VM disks must be in persistent mode. If you are using RDM’s you can migrate the mapping file if it is phyiscal or virutal (if it is virtual you can change it’s provisioning) but not the data.
Después de más de un año sin rendir certificaciones me decidí a ponerme al día y prepararme para el VCIX-DCV. Lamentablemente, por los cambios en las políticas de certificación de VMware me di cuenta que mi VCP-DCV6 estaba vencido y no iba a servir.
Al tener una certificación VCP-DCV6, no me era necesario rendir el examen vSphere 6.7 Foundations ni asistir a ningún curso. Por lo que directamente agendé el examen delta de vSphere 6.7. Con esto ya tenía una fecha limite, a partir de eso empecé a trabajar.
Lo primero que hice fue descargar la guía de del examen. En base a esa guía separé los temas en 3 “pilas”: Lo sé, no lo sé, hace falta un repaso. Entonces, por ejemplo: SIOC y NIOC entraron en la pila de lo sé, Fault Tolerance entró en la pila de repaso y temas como vCenter HA o VM encryption en la pila de no lo sé. Siendo la ultima pila la de mayor prioridad.
Desde la documentación oficial de VMware leí la teoría para cada tema en las pilas de repaso y no lo sé, también aprovechando la oferta de VMware Learning Zone gratis por seis meses elegí ver los videos de Exam Prep (hay uno para el foundations si tuvieras que prepararlo), hay un video por cada objetivo. Entonces, por ejemplo, Para el objetivo 1.2 – Identify vCenter high availability (HA) requirements leí todo lo referente a vCenter HA hasta estar seguro de que lo había entendido y después me vi el video relacionado del Exam Prep donde un instructor te da tips del estilo de: ¿En qué se diferencian vCenter HA y vSphere HA? ¿Cuántos componentes tiene? ¿Cuáles son los requisitos?
El día del examen rendí remoto con el modo proctored de Pearson Vue (en otro post te cuento la experiencia). El examen son 40 preguntas multiple choice y es en inglés, tenes 90 minutos para rendirlo (la página dice 75, pero te dan unos minutos extra por no ser un país donde el inglés es el idioma oficial). Por referencias de conocidos, el nivel de inglés puede afectar tu performance en el examen. Personalmente no me pareció dificil, muchas de las preguntas vienen desde vSphere 6.0 y al tener experiencia con la solución salen fácil. Una vez terminas con las preguntas podes revisarlas todas o directamente ir a la devolución. Al temrinar el examen sabes la nota, yo me saque 462/500 y la nota minima para aprobar es 300, también te podes imprimir el resultado. Más o menos a las 24 horas VMware me mandó el badge de la certificación mediante YourAcclaim.
En esta crónica te conté mi forma de preparar esta certificación, que en mi caso puntual ya había rendido antes y es un producto con el que tengo experiencia. Como siempre digo, es mi forma de hacer las cosas, no quiere decir que sea la única, simplemente es la que a mi me funciona.
Gracias por leer Por favor contame que te pareció el articulo.